With advancements in both policy and technology, there are now more options for registry-aligned SOC quantification than ever before: measure–remeasure, biogeochemical modeling (BGCM), model-assisted estimation (MAE), and digital soil mapping (DSM). Despite their differences, they all stem from just two fundamentally different inference philosophies: design-based and model-based inference. These philosophies determine how sampling design works, how uncertainty is calculated, and how easily a project can scale.
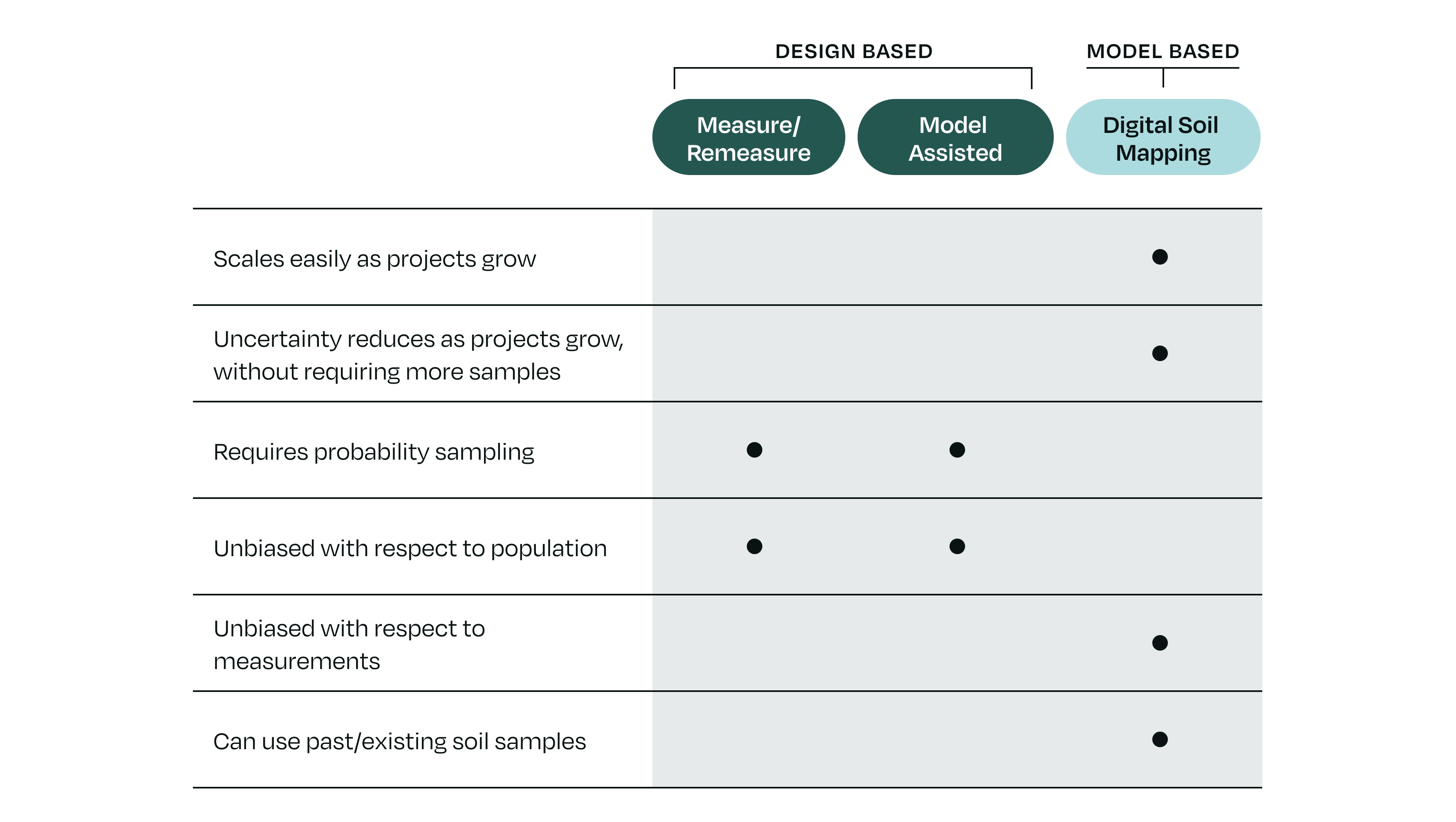
Design-based inference approaches — including both ‘model-assisted estimation’ and samples-only measure–remeasure — rely on probability sampling to guarantee unbiased estimates. They can use samples alone or incorporate a model to help, but the inference always depends on the sampling design. Because the project area must be defined up front, design-based approaches tend to be rigid and costly to scale, presenting challenges if you wish to add new fields to a project or if a farmer drops out during the process. Additionally, reducing uncertainty tends to rely on increasing the number of soil samples.
Model-based inference approaches, such as digital soil mapping, use models as the engine of inference. That shift creates important advantages: they’re flexible and easier to scale, they can incorporate historical and new data, and — uniquely — uncertainty lowers as the project area increases, without requiring a proportional increase in the number of physical soil samples.
Below, we break down these inference philosophies in more detail, and what they mean for uncertainty, scalability, and project economics.
Design-Based: grounded in probability sampling
A design-based approach starts with field measurements — soil samples collected according to a formal statistical probability sampling design (usually simple random or stratified random). The goal is to estimate carbon stocks and their changes directly from those measurements, without relying on a predictive model.
Because the results depend solely on how samples are collected, when sampling is executed properly, the statistical properties are very strong for estimating global quantities (e.g. means or totals):
- Estimates are unbiased with respect to the population, meaning on average, they aren’t systematically higher or lower than reality.
- Uncertainty can be obtained in a straightforward way.
The rigor of design-based inference comes from probability sampling — a sampling design where every location in the project area has a known and positive chance of being selected. In practice, that means defining the project area in advance, then selecting sampling locations according to that predefined probability sampling design. The statistical inference — the math that turns samples into project-level estimates — relies entirely on that design.
This creates some challenges and limitations. Once a probability sampling design is set, it is either difficult or impossible to expand without breaking the underlying statistical guarantees. This is complicated by the fact that, in practice, executing a true probability sample is extremely difficult. If even one randomly selected sampling point cannot be collected — due to grower dropout, weather, access issues, or a lost sample, for example — the probability design is technically broken. Because some fraction of points almost always fail in real-world sampling programs, perfectly executed probability samples are difficult to achieve in practice.
Even in the best case scenario, their reliance on probability sampling means design-based approaches:
- Cannot incorporate historical or existing measurements from previous projects and soil surveys
- Become rigid and costly when new fields or farmers are added to a project— making them difficult to scale for large or evolving projects that grow over time.
- Require additional samples to reduce uncertainty (i.e., if the resulting uncertainty is unsatisfactory, the only way to lower it is by adding more samples)
In short: when well executed, design-based approaches provide statistically grounded, unbiased, field and project level SOC stock values. However, real world conditions make them challenging to execute and their rigid statistical assumptions make them cumbersome for modern, distributed carbon projects — particularly ones with plans to scale in the future.
Model-Assisted: still design-based at its core
Some teams describe their methods as model-assisted — a term that can sound like a middle ground between design-based inference and model-based estimation. However, it’s not a separate philosophy. Model-assisted estimation is still design-based at its core, which means it comes with the challenges outlined above.
With model-assisted estimation, the statistical inference still depends entirely on the original sampling design, but auxiliary data (like satellite imagery or climate covariates) are used to improve the estimates. The model acts as a helper, not as the source of truth. That means even if the model is wrong, the inference is still valid by design.
In practice, the “model” in a model-assisted design is often simple — for example, a linear relationship between measured SOC and an ancillary variable like tillage status. It may improve precision, but it doesn’t replace the need for a basic probability sampling as a basis for making inference.
In short, with model-assisted inference:
- The estimates are unbiased with regard to the population, because they still rely on probability sampling.
- The model can help reduce variance (tightening uncertainty around the mean).
- Reliance on probability sampling makes it statistically elegant when sampling is successfully executed but operationally complex, rigid, and hard to scale.
- Though auxiliary models may provide incremental improvements, substantially reducing uncertainty almost always requires adding more field samples
This type of approach can work well in fixed, well-defined study areas where probability sampling is feasible. But for soil carbon projects that evolve over time — adding fields, practices, or partners — it can present limits, challenges, and inefficiencies. And, like other design-based approaches, model-assisted estimation still depends on a properly executed sampling design. In cases where samples are unrepresentative or missing, this approach can lead to inaccurate estimations, which in turn can result in overcrediting or undercrediting.
Model-Based: flexible, scalable, and practical for carbon projects
A model-based approach — the foundation of Digital Soil Mapping (DSM) — is a completely different philosophy. Here, the model is the core of the estimation process.
In model-based inference, soil samples don’t have to follow a probability sampling design (though they can). Instead, the placement of sampling locations can be optimized for the model in hand, and past soil samples can be incorporated when appropriate. Samples are used to train a model that predicts soil carbon stocks based on environmental covariates like climate, vegetation, and topography, or on-the-ground farm practice data like cover cropping and tillage status. Once a model is well-calibrated, additional sampling can be targeted and minimal, focused on fine-tuning or validating results rather than rebuilding the entire estimate from scratch.
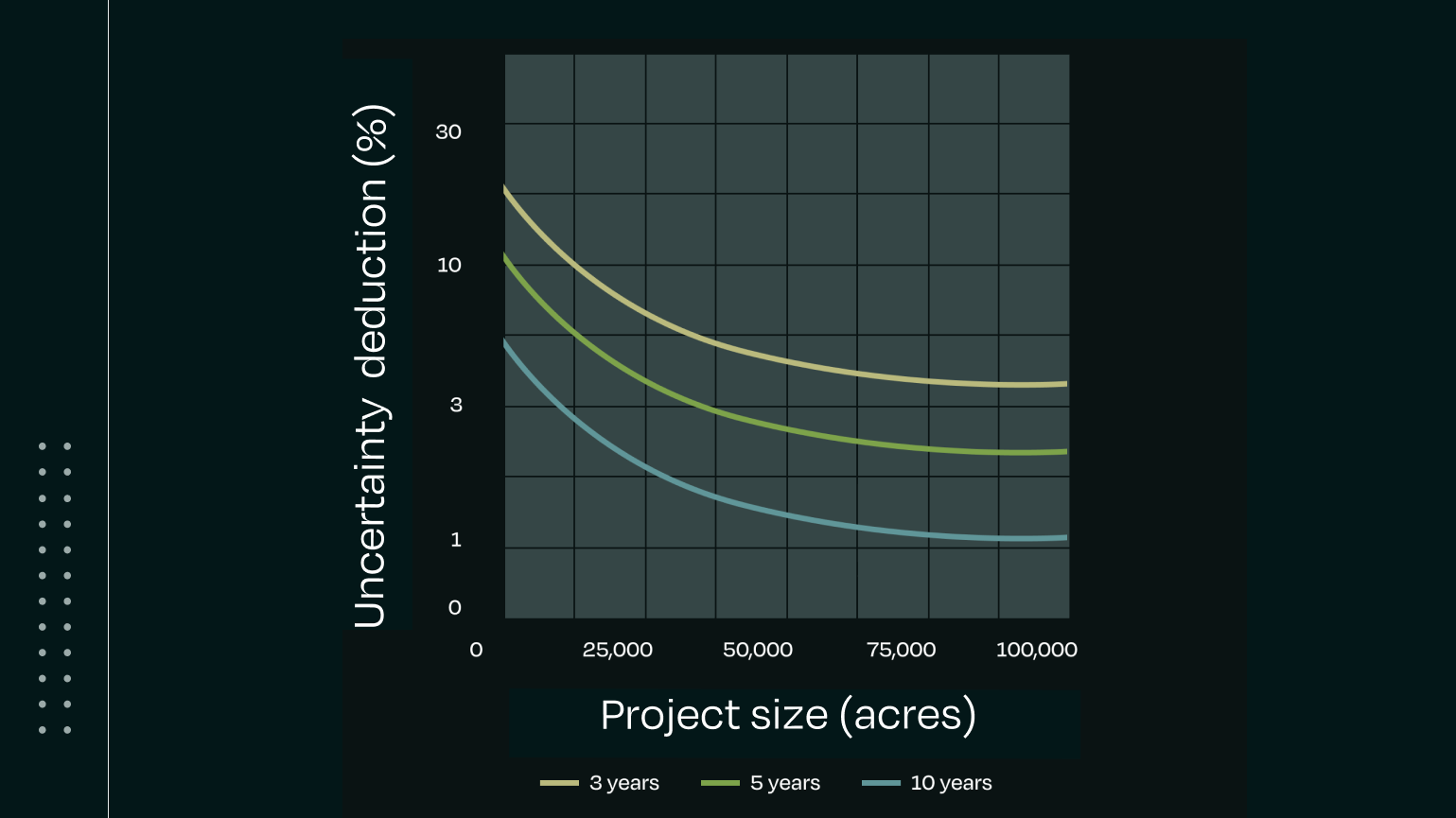
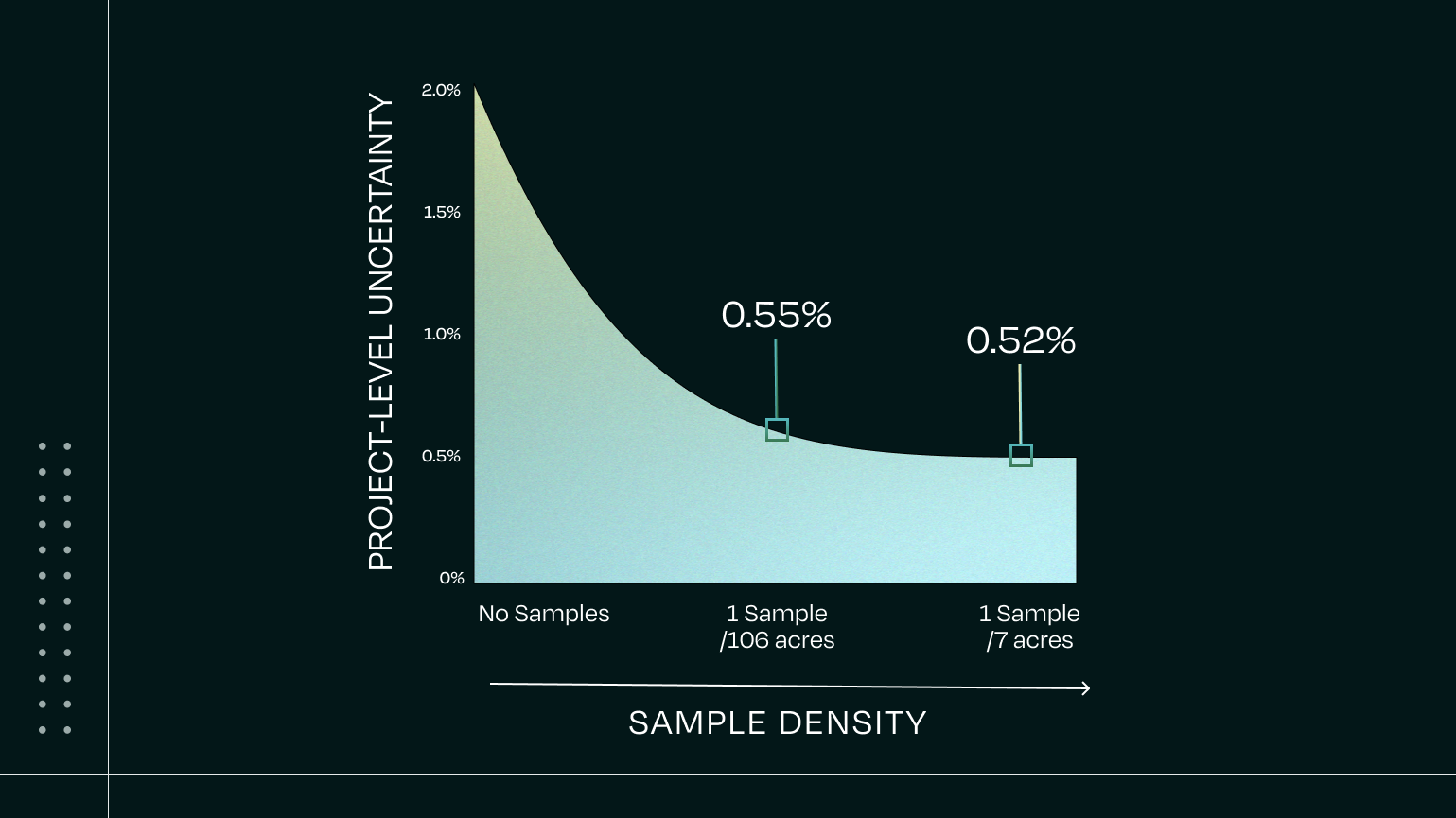
For all methods, uncertainty decreases as the number of measurements increases. This is a general statistical principle. When design-based approaches are used, increasing the number of measurements requires collecting more physical soil samples. Model-based approaches that use digital soil mapping behave differently; because their predictions are spatially continuous, the number of measurements (pixels) increases naturally with the project area. That means that as project size increases, uncertainty rapidly declines, without requiring more physical soil samples. For some project developers, this may support not only more efficient scaling, but also a lowered uncertainty reduction.
Key strengths of model-based approaches include:
- Flexibility and scalability: Models can incorporate new data and expand to new areas. They are portable across geographies, crops and land use types. High-resolution SOC maps can be generated across millions of hectares.
- Efficiency: Once trained, models can achieve high precision with fewer samples, since global and local data are used together to inform predictions.
- Quantified uncertainty: Because predictions are generated from a statistical model, uncertainty can be reported for every pixel or region.
- Uncertainty lowers as size increases: As the project area increases, uncertainty tends to decrease rapidly — without requiring a proportional increase in sampling.
These technical strengths work together to form a compounding effect: as projects expand, the relative cost of sampling decreases and overall uncertainty drops, improving project economics with lower costs and, potentially, more saleable credits. This benefit applies not only as a project scales but also as successive measurement events introduce new data — further reducing uncertainty and, in many cases, allowing sampling requirements to decrease over time while still meeting validation thresholds. Taken as a whole, this gives model-based systems both operational scalability and efficiency over time — advantages that sample-centric approaches cannot unlock without increasing sample counts.
Whereas design-based inference is assumed to be unbiased with respect to the population (because of the probability sampling design), model-based systems need to be unbiased with respect to the measurements. In practice, that means comparing model predictions to actual measurements from the project area that the model hasn’t seen before. Any systematic deviation is quantified and, if predictions are consistently high or low, the model is corrected.
For most project developers, this combination of empirical rigor and operational flexibility makes model-based inference the most practical path forward — delivering scalability, low uncertainty, and significant sampling and cost efficiencies.
Why this matters for carbon project developers
If your project covers a large or changing geography — or if you plan to scale over time — a model-based approach aligns better with your operational needs and helps future-proof your project.
Design-based methods, such as model-assisted estimation, offer textbook statistical rigor but are constrained by sampling requirements in a way that makes them rigid and costly to scale.
Model-based systems, in contrast, rely mostly on a statistical model, which can be calibrated, improved, purpose-built for the specific application, and adapted as new data becomes available. Model-based approaches that use digital soil mapping benefit from both spatial and temporal efficiencies, reducing relative sampling requirements and lowering uncertainty as more information accumulates — whether through increases in project scale or successive measurement events. The ability to lower uncertainty as projects grow without requiring a proportional increase in physical soil samples makes digital soil mapping attractive from a cost, operational, and ROI perspective.
At Perennial, we offer adaptable MMRV, selecting the best-fit monitoring approach for each project. Though we will sometimes recommend and embrace a design-based approach (for example, starting with samples-only measure-remeasure where data is extremely limited), we most often find model-based approaches are the most advantageous path for scalable, multi-year carbon projects. Whether we’re running digital soil mapping on its own or digital soil mapping together with a biogeochemical model, our approach is underpinned by ATLAS-SOC — our peer-reviewed, third-party validated digital soil mapping model, backed by years of R&D and hundreds of thousands of physical soil samples.
Fine-tuned with local samples, ATLAS-SOC provides efficient, low-uncertainty, registry-aligned quantification that scales across crops, geographies, and project types. Outcome-based validation ensures that model predictions are not just theoretically unbiased but empirically demonstrated — giving project developers and their credit buyers confidence that quantified changes reflect true on-the-ground outcomes.